OpenAI 三大語音模型怎麼用?Podcaster 的 AI 字幕、翻譯與錄音設備指南


AI 語音模型大爆發,跟你做 podcast 有什麼關係?
你做 podcast、配音、直播、廣播——那 2026 年 5 月發生的這些事,跟你有關。
5 月,AI voice 賽道一週內三家炸場:
- 5/7 OpenAI 一次發 3 個音訊 API 模型——即時對話、跨語翻譯、即時字幕
- 5/12 Forbes 報導,Google Gemini Live 被挖出 7 個尚未公開的隱藏 voice 模型
- 5/12 Meta 又把 Muse Spark 推進 voice conversations,讓 AI 可以打斷、切換話題、跨語言對話
你滑過新聞標題可能想:「這是開發者在玩的事,跟我做內容沒關係。」
不,有關係。而且不是「未來會有關」,是現在就有關:
- 你的競爭對手已經在用 AI 做雙語版本搶國際聽眾——一集 30 分鐘 OpenAI Translate API 成本不到台幣 35 元(不含 voice clone、後製、人工校對、平台費)
- 你的聽眾被 AI 工具養成壞胃口——沒自動字幕、沒 chapter、沒摘要的 podcast,被棄追的速度比以前快
- 配音員的工作流正在被重新定義——「真人聲音還能賣多少錢」這個問題正在被市場回答
2026 年要靠聲音吃飯,你得搞清楚 AI 在做什麼。不為了跟風,是為了知道哪些事 AI 已經做得比你好(讓它做)、哪些事 AI 還救不了(這就是你的護城河)。
這篇文章用 podcaster(播客主持人)、配音員、廣播從業者的角度拆 OpenAI 5/7 發的三個 voice 模型,並告訴你一件可能反直覺的事——
AI voice 工具越強,好麥克風跟好錄音介面變得越重要,不是越不重要。買對前端錄音設備,通常比反覆調 AI prompt 更優先。
核心邏輯一句話:傳統後製是「越修越好」,AI workflow 是「越錯越歪」——錄音前端髒一點點,後段就被放大成一坨錯字、翻錯方向、AI 講出來的「不是你說的那句話」。而且錯誤會連鎖:一個字聽錯,後面整段對話的方向都被帶歪。(這個概念第三大段會展開,這裡先給你個底。)
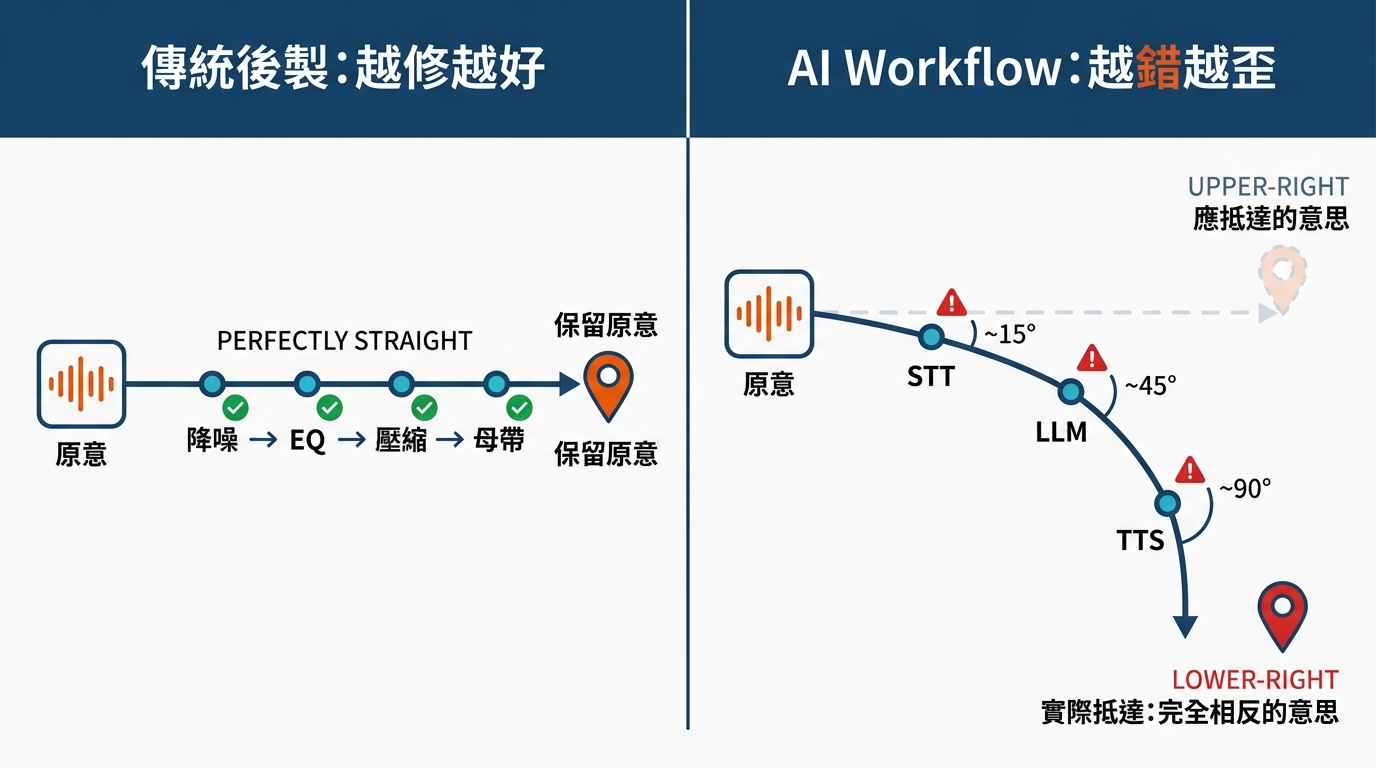
往下讀你會帶走:
- OpenAI 三個 voice 模型各自能讓你做什麼(含新增的 Cedar / Marin 兩個音色)
- 為什麼 AI 工具反而讓好麥克風變更重要
- 你現在的錄音夠不夠乾淨給 AI 用?5 項自我檢查
- 會影響 AI workflow 天花板的關鍵設備類型
(讀完約 12 分鐘——但會幫你少走很多彎路)
2026 OpenAI 語音模型比較:Podcaster 與配音員該怎麼選?
給 podcaster 的答案:gpt-realtime-translate 適合做多語版本測試、gpt-realtime-whisper 適合 live 字幕與訪談逐字稿、gpt-realtime-2 偏向互動式 voice agent(語音助理)。三者共同前提:原始錄音必須乾淨,否則 AI 會把雜訊、噗音、回音一起放大。
如果你趕時間,直接看這裡:
- 做即時互動 voice agent(podcast bot、AI 共同主持人) →
gpt-realtime-2(128K context window(上下文視窗),比 32K 大 4 倍,能容納更長單集脈絡) - 做雙語 / 多語 podcast、即時訪談翻譯 →
gpt-realtime-translate(70+ 種輸入語言 → 13 種輸出語言) - 自動產生字幕、會議轉錄、live podcast 字幕 →
gpt-realtime-whisper(streaming,邊講邊轉) - 你只想要高品質 AI 配音 / 聲音複製 → 暫時還是用 ElevenLabs(OpenAI 在這塊不是強項)
不論你用哪個模型,前端錄音品質永遠是 AI workflow 的天花板——後面有專門一節展開哪些設備類型會影響這個天花板。
不確定怎麼挑?繼續往下看,我們從每個模型在做什麼開始。
三家 voice AI 比較表:OpenAI vs ElevenLabs vs Gemini Live
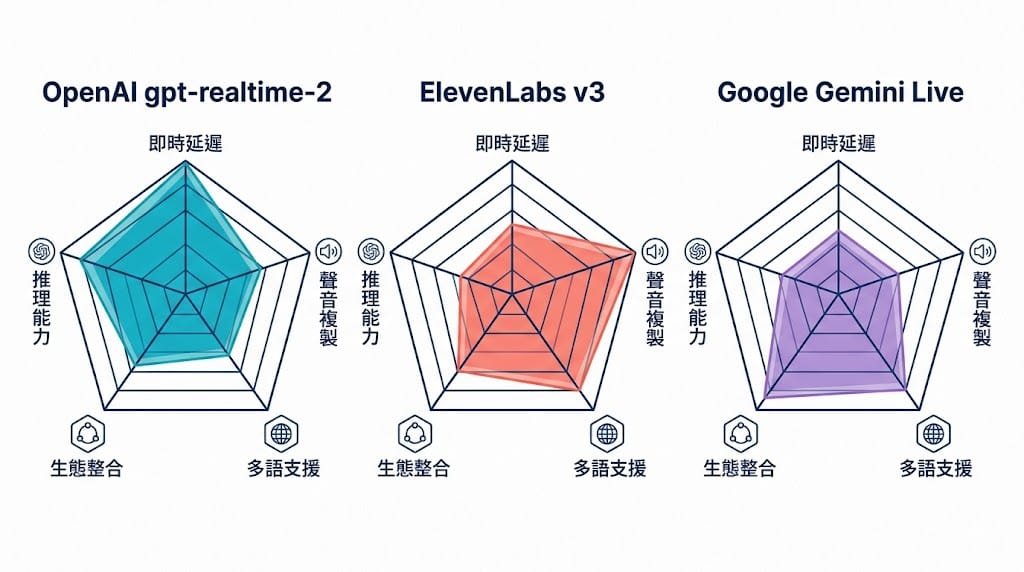
| 項目 | OpenAI gpt-realtime-2 | ElevenLabs v3 | Google Gemini Live |
|---|---|---|---|
| 強項 | 即時對話 + reasoning 一體化、128K context | 聲音複製、長篇 narration、情緒表達 | Google 生態整合、行動裝置原生 |
| 首句延遲 | ~1.1 秒(minimal reasoning)/ 2.3 秒(high reasoning)¹ | 較高延遲,非即時對話取向(Flash v2.5 才是 ~75ms) | 低延遲、比前代更快;官方未公布精確毫秒數 |
| 定價 | $32/M input audio、$64/M output、cached $0.40/M(token 計費;實際每分鐘成本取決於輸入/輸出音訊長度、文字/圖片輸入、對話回合累積與 cache 命中) | 免費方案;Starter $6/月起,Professional Voice Clone 需 Creator 以上 | 依 Google 官方 Gemini API / Enterprise 方案;本文不列精確價格 |
| 適合做 | 互動式 voice agent、AI 共同主持人 | 有聲書、配音、品牌人聲 | Gemini app / Search Live / Google 產品整合應用 |
| 聲音複製 | 不公開支援 | 平台支援 voice cloning(聲音複製);可搭配 v3 / TTS 工作流使用 | 公開文件未列完整 voice cloning 工作流 |
| 多語 | 支援多語;官方未列精確數字 | 70+ 種(以 ElevenLabs 官方 models 頁為準) | 未公開明確數字 |
¹ 延遲數字來自第三方 Artificial Analysis benchmark 實測(1.12s / 2.33s);OpenAI 官方只確認 reasoning effort 會影響 latency,未公布精確 TTFA。
實務建議:很多 podcast 工作流會混用兩三家——OpenAI 處理即時互動、ElevenLabs 處理需要 host 個人聲音的環節(雙語版 host、品牌 intro、廣告插播)、Gemini Live 在行動裝置上補位。不是非此即彼。
OpenAI 三個模型快速比較表
| 模型 | 主要用途 | 首句延遲 | 定價 | 支援語言 | Context |
|---|---|---|---|---|---|
| gpt-realtime-2 | 即時雙向對話、voice agent | ~1.1s¹ | $32/M in、$64/M out、cached $0.40/M | 支援多語;官方未列精確語言數 | 128K tokens(從 32K 升級 4 倍) |
| gpt-realtime-translate | 即時語音翻譯 | 低延遲串流 | $0.034 / 分鐘 | 70+ → 13 種 | — |
| gpt-realtime-whisper | 即時語音轉文字(字幕用) | 低延遲串流 | $0.017 / 分鐘 | 即時語音轉文字;官方未列精確語言數 | — |
¹ 同前表註:第三方 Artificial Analysis 實測;OpenAI 官方只確認 reasoning effort 影響 latency,未公布精確 TTFA。
三個模型都是給開發者透過 API 整合進產品的,不是給一般用戶直接用的 ChatGPT 介面。但理解能力邊界,能讓你判斷市面上會出現哪些新工具,以及怎麼把它們納入工作流。
Cedar 與 Marin:這次附送的兩個新音色
除了模型升級,OpenAI 在 Realtime API 新增了兩個專屬音色:
- Cedar / Marin:OpenAI 官方在 Realtime API 建議使用的高品質聲音;性別感、聲線特質、適合場景以實際試聽為準
- 試聽連結:OpenAI Playground
對配音員而言,這是個矛盾的好消息:AI 配音越像真人,「真人配音的差異化價值」就越貴——但前提是:你的「真人訊號」要有夠多細節、夠有個人特色——這些是目前 AI 還複製不來的東西。後面會展開講。
Use case 1:用 gpt-realtime-translate 做雙語 podcast
給 podcaster 的答案:這是三個模型裡對 podcaster 變現潛力最直接的一個。一集 30 分鐘的中文 podcast 翻成英文音檔,OpenAI Translate API 成本不到台幣 35 元(不含後製與其他費用)。但翻譯後不會完全保留原 host 聲音特徵——若品牌一致性重要,要搭 ElevenLabs voice cloning。
為什麼這個值得做
過去你想把中文 podcast 出英文版,要嘛:
- 請翻譯把逐字稿翻成英文 → 找英文配音員重錄 → 後製混音(成本:每集數千到上萬台幣,週期:1–2 週)
- 用 Google Translate 出字幕 → 假裝你做了英文版(聽眾流失率超高)
現在流程壓縮到:把原始音檔送進 API → 拿到目標語言音檔,一集 30 分鐘 OpenAI Translate API 成本不到台幣 35 元(不含後製與其他費用),週期分鐘級。
實際 workflow
建議分兩條:
- 低成本路線(適合測試市場):原音 → Translate 直接出目標語言音檔 → 上架 → 看數據
- 品牌路線(適合維持 host 個人聲音):原音 → Translate 出文字稿 → 用 ElevenLabs voice clone 你的聲音配 → 上架
第二條成本高(ElevenLabs 訂閱費 + 一次性 voice clone 設置),但能維持「這還是同一個 host」的品牌一致性。
但有個前提
翻譯模型對「乾淨的原音」很敏感。如果你的原始錄音底噪高、口齒不清、有回音,Translate 出來的結果會:
- 翻錯字(背景雜音被當成語意片段)
- 節奏怪(停頓沒切對)
- 聲音飄(合成端解析不出原本語氣)
這就是為什麼前端錄音設備重要。後面會展開講。
Use case 2:用 gpt-realtime-whisper 自動產字幕
給 podcaster 的答案:若不需要即時串流體驗,大部分字幕場景可以先用原本 Whisper API 測試(成本較低)。gpt-realtime-whisper 真正用得到的是「需要即時體驗」的場景——live podcast、voice agent 內部模組、訪談即時記錄。
Whisper 不是新東西——OpenAI 從 2022 年就 open source 了 Whisper 模型。但這次的 gpt-realtime-whisper 不一樣:
- 原本的 Whisper API($0.006/分鐘):批次處理,要等整個檔案上傳完才開始轉
- gpt-realtime-whisper($0.017/分鐘):串流處理,邊講邊轉,延遲低
自動字幕實用性的真相
市面上很多 podcast 平台(Spotify、Apple Podcasts)都已自動產字幕。但這些字幕在中文、台語、英文夾雜的內容下,錯字率常明顯升高。
真的要 SEO 友善 / 聽障無障礙的字幕,建議走自己跑 Whisper 的路線,加上:
- 專業領域辭典(把你領域常用的人名、產品名、術語先列進去)
- 人工校對(最後仍需要人工把關)
- 分段標題(時間軸 chapter,提升讀者跳讀體驗)
同樣,Whisper 的轉錄精度跟原始音訊清晰度成正比。底噪高、近距離噗音、sibilance(齒音)嚴重的錄音,Whisper 會卡住、漏字、誤判段落。
Use case 3:用 gpt-realtime-2 做互動 voice agent
給 podcaster 的答案:這是三個模型裡最未來、也最不普及的一個。對純內容創作者,比較實際的做法是等市面上有 podcast 平台把這功能包好給你用,再決定要不要付費訂閱。但128K context window 是大賣點——比舊版 32K 大 4 倍,能容納顯著更長的單集脈絡,AI 主持人較不容易在錄到一半就「忘記」前面講了什麼。
gpt-realtime-2 把過去的「聽 → 想 → 說」三個獨立步驟(STT(語音轉文字)→ LLM(大型語言模型)→ TTS(語音合成))合併成單一模型,端到端 first-audio 延遲約 1.1 秒(minimal reasoning)¹,可減少 STT→LLM→TTS 串接延遲,實際速度依實作而定。
¹ 同前表註:第三方 Artificial Analysis 實測;OpenAI 官方只確認 reasoning effort 影響 latency,未公布精確 TTFA。
對 podcast 來說,這開啟了幾種新可能:
- AI 共同主持人:你錄 podcast 時,AI 即時回應、補充、提出問題(更長的單集脈絡能維持在 context 內,減少掉脈絡的機率)
- 聽眾互動式 podcast:聽眾在 app 內可以直接跟 podcast 角色對話
- 內容衍生品:把 podcast 內容做成 voice agent,讓聽眾可以「跟你的歷史內容對話」
但這些 use case 都需要產品開發能力。對純內容創作者,比較實際的做法是等 podcast 平台把這個功能包好。
128K context window 具體對 podcaster 的影響
用 podcast 場景比喻:
| 項目 | 舊版 32K tokens | 新版 128K tokens |
|---|---|---|
| Context window | 32K tokens | 128K tokens(為 32K 的 4 倍) |
| 長對話脈絡保持 | 較易掉脈絡 | 更容易維持脈絡 |
| 聽眾互動 agent | 只能問單集片段 | 可容納更長單集內容;若要支援整個 podcast 系列,仍需要檢索 / 知識庫設計 |
註:實際可容納音訊長度取決於 token 化方式、輸入格式與流程設計。
AI 救不了的事:為什麼前端錄音是天花板,不是錦上添花
給 podcaster 的答案:AI voice 工具越強,「我有 AI 後製,前端隨便錄就好」這個想法錯得越徹底。AI 對訊號品質的依賴比傳統後製還嚴格,因為 AI 的誤差是放大式而不是遞減式。
這節是這整篇文章最重要的部分。AI voice 工具越強,越多人犯一個盲點:
「我有 AI 後製了,前端隨便錄就好」
這個想法錯得徹底。原因有四:
原因 1:AI 的 error propagation(誤差是放大式的)
傳統後製鏈:錄音 → 降噪 → EQ → 壓縮 → 母帶。每個環節都是遞減式修正,最終損耗有限。
AI 鏈:錄音 → STT 模型 → LLM → TTS 模型。每個環節都是放大式誤差——STT 錯一個字,LLM 會基於這個錯字往下推理,TTS 會把推理結果合成成聽起來「很自然但說錯的話」。
底噪、回音、近距離噗音不只是「聽起來髒」,是會直接讓 AI 在某些關鍵字上判斷錯誤,可能一路影響後續的 LLM 判斷與 TTS 輸出。
原因 2:Voice cloning 的品質 floor
如果你想用 ElevenLabs 複製自己的聲音做 AI 主持人,它的天花板就是你給它的原始錄音的天花板。
用筆電內建麥 / Logitech 桌面麥 / 藍牙耳機麥錄下來餵 ElevenLabs,你會得到一個有電子味、有底噪、有壓縮 artifact(壓縮雜訊)的「AI 自己」。然後聽眾會問:「你的 podcast 為什麼聽起來怪怪的?」
真正能用的 voice cloning 訓練資料需要:
- XLR 麥克風 + 低噪錄音介面;若使用電容麥或 inline preamp(如 FetHead / Cloudlifter),需依設備官方規格確認是否需要 48V phantom power(幻象電源)
- 安靜、低背景噪音、無明顯房間殘響的單一人聲錄音環境
- Instant Voice Cloning:1–2 分鐘乾淨人聲即可測試;Professional Voice Clone:官方建議至少 30 分鐘,品質目標接近 2–3 小時
原因 3:台灣錄音環境的典型痛點
台灣多數創作者在家錄音,常見的環境問題會直接拖垮 AI workflow:
- 背景雜音——機車聲、街道車流、樓上施工、隔壁裝潢
- 持續性低頻——冷氣壓縮機、抽風扇、電腦風扇嗡嗡聲
- 房間殘響(reverb)——多數家庭環境沒做聲學處理,磁磚、玻璃、空牆反射
- 近場噪音——鍵盤聲、滑鼠 click、紙張翻動聲
這類「非持續性」噪音特別會讓 AI 轉錄誤判——背景一聲機車轟過,Whisper 可能就在那個句尾掉一段字。所以選用抗噪性佳的動圈麥克風是台灣創作者的首選。
原因 4:Translation 的語境理解
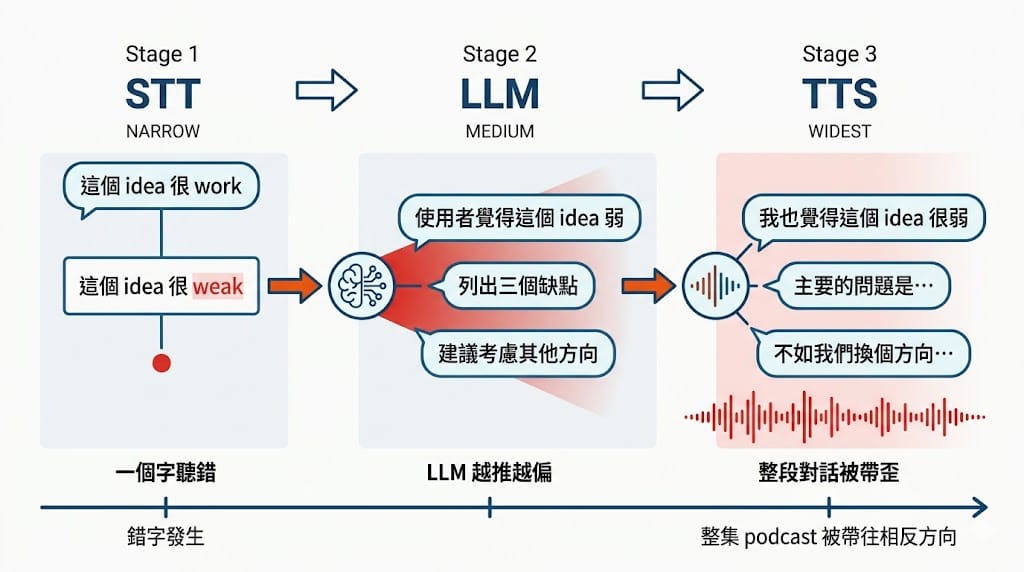
gpt-realtime-translate 翻譯品質非常依賴能不能聽清楚原本的語意片段。中文 podcast 常常會混雜英文短詞(「我覺得這個 idea 很 work」),AI 在這種多語切換場景下,底噪會直接讓它把英文字判別成另一個發音相近、但意思完全相反的字。
結果就是:你原本講「這個 idea 很 work」(可行),AI 聽成「這個 idea 很 weak」(弱爆)——這一句翻轉了,已經夠糟。
但更糟的是後面的連鎖反應。LLM 會以「使用者覺得這個 idea 弱」當前提繼續推理,接下來幾分鐘的對話、回應、追問、建議,全部建立在這個錯誤判斷上。如果是 AI 共同主持人,它會順著「弱」往下講、順著「弱」追問、順著「弱」收尾——你回頭聽會發現:AI 把你力推的 idea變成要砍掉的 idea,而且每一句聽起來都很自然、很順、很有邏輯,因為它真的有邏輯——只是建立在錯的前提上。再翻譯成英文輸出,雙語版聽眾收到的是一場「主持人嫌棄自己 idea」的 podcast。傳統後製不會發生這種事,AI workflow 會。
這不是 AI 不夠強,是物理層的問題——你給它的訊號不夠乾淨,演算法做不出 magic。
如果這段對你有幫助,歡迎轉給你身邊正在做 podcast、配音、廣播、自媒體的朋友 — 幫他們少走半年的彎路。
你現在的錄音夠不夠乾淨給 AI 用?5 項自我檢查
在花錢買新設備前,先用這 5 項檢查你現有的錄音狀態:
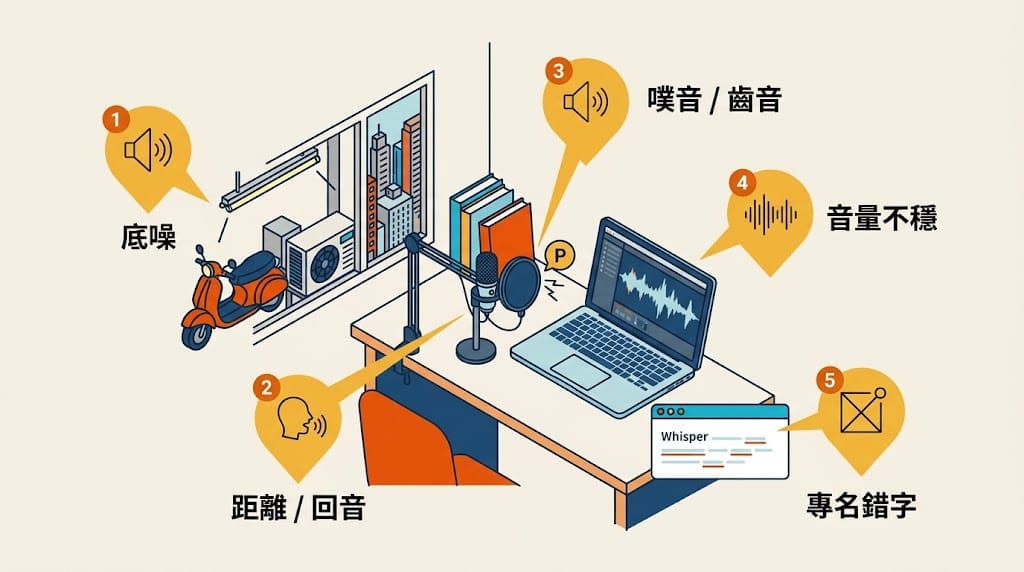
| # | 檢查項目 | 怎麼自測 | 不過關的後果 |
|---|---|---|---|
| 1 | 房間底噪是否明顯 | 麥克風開著、自己安靜不出聲,聽 10 秒。冷氣/機車/街道聲/螢光燈嗡嗡聲明顯嗎? | 底噪會被 AI translation/voice cloning 整段放大,輸出聽起來「悶悶的」、像隔著毛玻璃講話 |
| 2 | 人聲是否貼近清楚、無回音 | 錄一段測試,聽起來像「就在耳邊講話」還是「房間另一頭講話」? | 遠麥/回音會讓 Whisper 斷句、Translate 翻錯,字幕變天書 |
| 3 | 是否有噗音/齒音/噴麥 | 講帶 ㄆ/ㄅ/s/ch 音節的句子,聽喇叭爆音/刺耳嗎? | AI voice cloning 會把噗音當你聲音特徵複製,做出「永遠在噴口水」的 AI 主持人 |
| 4 | 整段錄音音量是否穩定 | 看 DAW(數位音訊工作站)波形,整段動態落差是否明顯偏大、忽大忽小? | 音量不穩 → AI 模型對「小聲段落」辨識率掉、「大聲段落」會壓縮失真 |
| 5 | 專有名詞/人名/品牌名轉錄是否常錯 | 把錄音丟 Whisper 跑一遍,看 Cubase/Apollo/SM7B 這類專名有沒有變音譯怪字 | 專名錯字會被 LLM 沿用推論,後面 chain 全錯,字幕跟翻譯都不能用 |
判讀標準:若多項不過關,你的 AI workflow 結果很可能打折——不是 AI 不夠強,是你給它的訊號不夠乾淨。先處理錄音前端,再花時間調 AI prompt。
會影響 AI workflow 天花板的關鍵設備
這節不是購買清單。如果你在思考自己的錄音 setup 怎麼配,下面這幾個類別會直接決定 AI workflow 能處理到什麼品質:
- 動圈麥克風:抗環境噪音、適合台灣家錄場景,是 AI workflow 最不易出包的起點
- 廣播級動圈麥克風(業界常以 SHURE SM7B 為代表):podcast、訪談、廣播圈長期使用的工作主力,輸出穩定、音色辨識度高
- 大振膜電容麥克風(業界常以 Neumann TLM-103 這個等級為代表):細節豐富、底噪低,適合需要乾淨人聲特徵的 voice cloning 訓練素材
- 錄音介面:48V phantom power、足夠 gain、低噪前級——是麥克風訊號乾淨度的第一道把關
- 監聽耳機:能在錄製當下聽出底噪、破音、節奏問題,比後製時補救容易得多
我們刻意不在這篇文章裡點名特定型號——適合你的 setup 取決於內容類型、錄音環境、預算與工作流。希望你看完知道為什麼這些類別重要,而不是看完一份購物車。
THINK2 除了長期代理音訊設備之外,也正在把服務延伸到 AI workflow 整合與設備搭配諮詢。對需要把錄音 setup、AI 工具、後製流程串成一條鏈的 podcaster、自媒體工作者、新創團隊,我們可以是你的供應商與顧問。想針對自己的需求聊聊,歡迎透過 LINE 找我們。

結語:AI 是工具,不是替代品
OpenAI 5 月發的這三個模型確實會改變很多人的工作流——多語 podcast 變便宜、即時字幕變即時、互動 voice agent 變可行。
但 AI workflow 的天花板永遠是你給它的原始訊號品質。買對麥克風、買對錄音介面,通常比反覆調 prompt 更優先。
而真人主持的差異化價值,在 AI slop 氾濫的時代會越來越貴——這不是要你拒絕 AI,而是要你用對的方式跟 AI 共處:
- 用 AI 處理機械工作(字幕、翻譯、簡單 voice agent)
- 把人力時間留給內容本身(採訪、故事、情緒、品牌人格)
- 用專業設備把屬於你的人格、風格、觀點好好呈現出來——這些 AI 還複製不來的東西,才是你的護城河
本文資料來源:OpenAI 官方發布(2026/5/7)、OpenAI API 文件(pricing / model docs / realtime cost docs)、ElevenLabs 官方文件(models / pricing / voice cloning)、Google Gemini 3.1 Flash Live 官方頁、Meta Muse Spark 官方公告(about.fb.com)、Forbes(Paul Monckton 2026/5/12 揭露 Gemini Live 隱藏模型)、Artificial Analysis 第三方 benchmark(gpt-realtime-2 延遲)、Shure SM7B 官方頁。本文撰寫於 2026/5/14,校稿於 2026/5/16。AI 模型定價與規格可能變動,請以 OpenAI、ElevenLabs、Google、Meta 官方文件為準。
本文由 Friday/THINK2 音訊團隊整理。THINK2 專注錄音設備、麥克風、宅錄、Podcast 與直播收音應用,更多官方通路與售後資訊請見 THINK2 官方通路/關於我們。